

IBM y Linux: en el ciclo de vida de Inteligencia Artificial (IA), usamos datos para construir modelos para la automatización de la toma de decisiones. Los conjuntos de datos, modelos y pipelines (que son los que nos llevan desde los sets de datos sin procesar a modelos implementados) se convierten en los tres pilares más críticos del ciclo de vida de IA. Debido a la gran cantidad de pasos en los que hay que trabajar en el ciclo de vida de datos e IA, el proceso de construir un modelo puede dividirse entre diversos equipos y dar lugar a numerosas duplicaciones cuando se generan Datasets, Features, Modelos, Pipelines y Pipeline tasks similares. A su vez, esto plantea un fuerte desafío en cuanto a rastreabilidad, gobierno, gestión de riesgos, seguimiento de lineage y colección de metadatos.
IBM y Linux crearon Machine Learning eXchange (MLX)
Para solucionar los problemas anteriormente mencionados, necesitamos un repositorio central en el que todos los tipos de activos diferentes, como Datasets, Modelos y Pipelines sean almacenados para ser compartidos y reutilizados transversalmente en la organización. Contar con Datasets, Modelos y Pipelines verificados y comprobados, con controles de alta calidad, con las licencias adecuadas y el seguimiento de linaje, aumenta enormemente la velocidad y eficiencia del ciclo de vida de IA.
Con el objetivo de resolver tales desafíos, IBM y Linux Foundation AI and Data (LFAI and Data) unen esfuerzos para anunciar Machine Learning eXchange (MLX), un Catálogo de Activos de Datos e IA y un engine de Ejecución en Open Source y también Open Governance.
Machine Learning eXchange (MLX) permite cargar, registrar, ejecutar e implementar pipelines de IA y componentes de pipelines, modelos, datasets y notebooks.
Arquitectura Machine Learning eXchange
Machine Learning eXchange proporciona:
- Generación automatizada de modelos de código de pipeline para ejecutar modelos, datasets y notebooks registrados
- Pipelines engine impulsado por Kubeflow Pipelines en Tekton, la base de Watson Studio Pipelines
- Registro para Componentes de Kubeflow Pipeline
- Gestión de Datasets con Datashim
- Service Engine KFServing
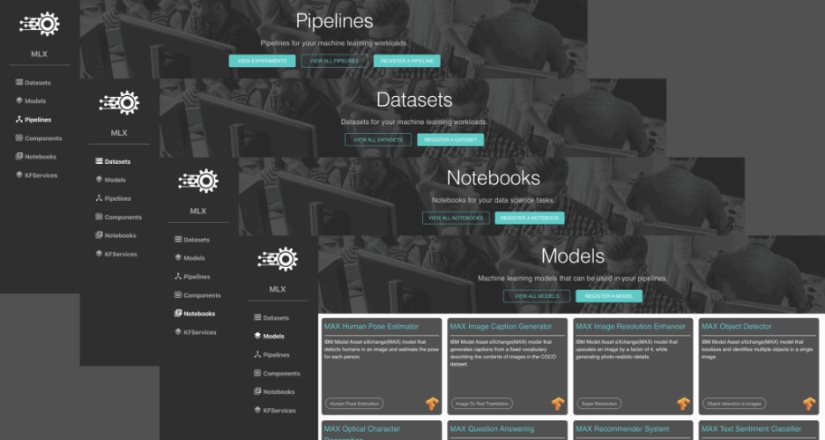
Activos del catálogo de Machine Learning eXchange
Pipelines
En el Aprendizaje Automático o Machine Learning (ML), es común realizar una secuencia de tareas para procesar y también aprender de los datos, todo puede llevarse en un pipeline. Los Machine Learning Pipelines son:
- Una forma coherente de colaborar en proyectos de ciencia de datos más allá de los límites de la organización y el equipo.
- Una colección de tareas generales encapsuladas como componentes de pipeline que encajan como ladrillos de lego
- Un lugar único para los interesados en entrenar, validar, implementar y monitorear modelos de IA
Algunos ejemplos de Pipelines incluidos en el catálogo MLX: Trusted AI Pipeline (with AI Fairness 360 and Adversarial Robustness 360), Hyperparameter Tuning y Nested Pipeline.
Componentes de Pipeline
Un componente de pipeline es un conjunto de código autónomo que realiza un paso en el workflow de ML (pipeline), como la adquisición de datos, el pre-procesamiento de datos, la transformación de datos, el entrenamiento de modelos, etc. Un componente es un bloque de código que realiza una tarea atómica y se puede escribir en cualquier lenguaje de programación y utilizando cualquier framework. Algunos de los componentes de pipeline que se incluyen en el catálogo MLX son, entre otros: Create Dataset Volume with DataShim, Deploy a Model on Kubernetes, Adversarial Robustness Evaluation y Model Fairness Check.
Modelos
MLX proporciona una colección de modelos de deep learning gratuitos, de código abierto y de última generación para dominios de aplicaciones comunes. La lista seleccionada incluye modelos desplegables que pueden ejecutarse como microservicio en Kubernetes u OpenShift. Y modelos entrenables, que pueden entrenarse por los usuarios con sus propios datos. Algunos modelos incluidos en el catálogo MLX son, entre otros: Human Pose Estimator, Image Caption Generator, Recommender System y Toxic Comment Classifier.
Datasets
El catálogo MLX contiene conjuntos de datos reutilizables y aprovecha Datashim para hacer que los conjuntos de datos estén disponibles para otros activos MLX como notebooks, modelos y pipelines en forma de volúmenes Kubernetes. Algunos de los datasets que contiene el catálogo MLX son, entre otros: Finance Proposition Bank, NOAA Weather Data – JFK Airport, Thematic Clustering of Sentences y también TensorFlow Speech Commands.
Notebooks
La aplicación web de código abierto Jupyter notebook permite a los científicos de datos crear y compartir documentos que contienen código ejecutable, ecuaciones, visualizaciones y texto narrativo. MLX puede ejecutar Jupyter notebooks como contenidos de pipeline autónomo aprovechando el proyecto Elyra-AI. Algunas de las notebooks que contiene el catálogo MLX son, entre otros: AIF360 Bias Detection, ART Poisoning Attack, JFK Airport Analysis y Project CodeNet Language Classification.
Súmese para construir AI Marketplace nativo de nube en Kubernetes
Machine Learning eXchange proporciona un marketplace y una plataforma para que los científicos de datos compartan, ejecuten y colaboren en sus activos. Ahora se puede usar para alojar y colaborar con activos de Datos e IA dentro del mismo equipo de trabajo y con otros equipos. Haz parte del repo de github de Machine Learning eXchange, pruébalo, cuéntanos qué opinas y comparte tus problemas. También puedes contactarte de las siguientes maneras:
● Para contribuir y construir Pipelines de Machine Learning en OpenShift y Kubernetes, súmate al proyecto Kubeflow Pipelines on Tekton. ¡No dudes en enviarnos comentarios, preguntas y feedback!
● Para desplegar Modelos de Machine Learning en producción, conoce sobre el proyecto KFServing.
Enlaces clave de MLX: Website, GitHub, Artwork,
Listas de distribución: MLX-Announce, MLX-Technical Discuss, MLX-TSC
Si no quieres perderte ningún detalle acerca de videojuegos, tecnología, anime y series, mantente alerta de nuestra sección de noticias.