


¡Más novedades del GTC 2022! Esta vez te venimos a platicar un poco más de los dos nuevos servicios de cloud presentados por NVIDIA. El primero de ellos se trata del Servicio NVIDIA NeMo Large Language Model, y el segundo es el Servicio NVIDIA BioNeMo LLM. Ambos destinados para que los desarrolladores puedan adaptar fácilmente los LLM y aplicaciones IA personalizadas.
El Servicio NeMo LLM permite a los desarrolladores adaptar rápidamente una serie de modelos de fundación previamente entrenados. Utilizando un método de entrenamiento llamado aprendizaje rápido en la infraestructura administrada por NVIDIA. Además, el Servicio NVIDIA BioNeMo es una Interfaz de programación de aplicaciones (API) de cloud. Que expande los casos de uso de LLM más allá del idioma y en aplicaciones científicas. Para acelerar el descubrimiento de fármacos para las empresas farmacéuticas y biotecnológicas.
“Los grandes modelos de idiomas tienen el potencial de transformar todas las industrias. La capacidad de ajustar los modelos de base pone el poder de los LLM al alcance de millones de desarrolladores que ahora pueden crear servicios de idiomas y potenciar los descubrimientos científicos sin necesidad de crear un enorme modelo desde cero”.
Jensen Huang, fundador y CEO de NVIDIA.
El Servicio NeMo LLM Aumenta la Precisión con el Aprendizaje con Instrucciones, Acelera las Implementaciones
Con el Servicio NeMo LLM, los desarrolladores pueden usar sus propios datos de entrenamiento para personalizar modelos de base. Que van desde 3,000 millones de parámetros, hasta Megatron 530B, uno de los LLM más grandes del mundo. El proceso toma unos pocos minutos a horas en comparación con las semanas o meses que se necesitan para entrenar un modelo desde cero.
Los modelos se personalizan con aprendizaje rápido, que utiliza una técnica llamada p-tuning. Esto permite a los desarrolladores usar solo unos cientos de ejemplos. Para adaptar rápidamente los modelos de base que originalmente se entrenaron con miles de millones de puntos de datos. El proceso de personalización genera tokens de prompt específicos de la tarea. Que luego se combinan con los modelos de base para ofrecer una mayor precisión y respuestas más relevantes para casos de uso específicos.
Los desarrolladores pueden personalizar para varios casos de uso con el mismo modelo y generar muchos tokens de prompt diferentes. Una función de área de pruebas proporciona una opción sin código para experimentar e interactuar fácilmente con los modelos. Lo que aumenta aún más la eficacia y la accesibilidad de los LLM para casos de uso específicos de la industria.
Una vez que están listos para implementarse, los modelos ajustados se pueden ejecutar en instancias de cloud, en sistemas locales o a través de una API.

El Servicio BioNeMo LLM Permite a los Investigadores Aprovechar el Poder de los Grandes Modelos
El Servicio NVIDIA BioNeMo incluye dos nuevos modelos de Idiomas BioNeMo para aplicaciones de química y biología. Proporciona soporte para datos de proteínas, ADN y bioquímica para ayudar a los investigadores a descubrir patrones y conocimientos en secuencias biológicas.
Servicio NVIDIA BioNeMo permite a los investigadores ampliar el alcance de su trabajo aprovechando modelos que contienen miles de millones de parámetros. Estos modelos más grandes pueden almacenar más información sobre la estructura de las proteínas, las relaciones evolutivas entre los genes e incluso generar nuevas biomoléculas para aplicaciones terapéuticas.
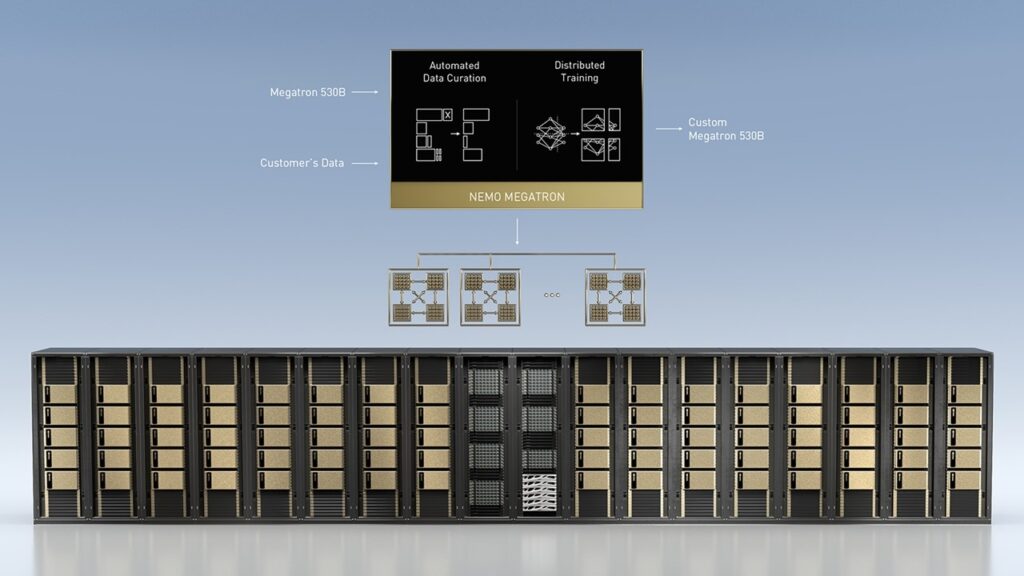
La API de Cloud Proporciona Acceso a Modelos Megatron 530B y Otros Modelos Listos para Usar
Además de ajustar los modelos de base, los servicios de LLM incluyen la opción de usar modelos personalizados y listos para usar a través de una API de cloud.
Esto les da a los desarrolladores acceso a una amplia gama de LLM previamente entrenados, incluido uno de los más grandes del mundo, Megatron 530B, con 530,000 millones de parámetros. También proporciona acceso a modelos T5 y GPT-3 creados con el framework NVIDIA NeMo Megatron , ahora disponible en versión beta abierta, para admitir una amplia gama de aplicaciones y requisitos de servicio multilingües.
Los líderes en las industrias automotriz, de computación, educación, atención de la salud, telecomunicaciones y otras están usando NeMo Megatron para ofrecer servicios pioneros a clientes en chino, inglés, coreano, sueco y otros idiomas.
Disponibilidad
Se espera que los servicios neMo LLM y BioNeMo y las API de cloud estén disponibles en acceso anticipado a partir del próximo mes. Los desarrolladores pueden solicitarlos ahora para obtener más detalles.
La versión beta del framework NeMo Megatron está disponible mediante NVIDIA NGC y está optimizada para ejecutarse en NVIDIA DGX Foundry y NVIDIA DGX SuperPOD, así como instancias de cloud aceleradas de Amazon Web Services, Microsoft Azure y Oracle Cloud Infrastructure.
Si quieres conocer todo lo que se anuncio durante el GTC 2022, date una vuelta por nuestro sitio Geekzilla.tech para infromarte con las mejores noticias sobre tecnología.