


Tabla de contenidos
Los atacantes pueden comprometer la integridad de los modelos de Deep Learning durante el entrenamiento o el tiempo de ejecución, robar información propietaria de los modelos implementados, o incluso revelar información personal confidencial contenida en los datos de entrenamiento. La mayor parte de la investigación hasta la fecha se ha enfocado en ataques contra modelos discriminativos. Como modelos de clasificación o regresión, y sistemas para reconocimiento de objetos o reconocimiento de habla automatizado.
El equipo de IBM descubrió nuevas amenazas contra el Deep Learning y desarrolló defensas para un tipo distinto de modelos de inteligencia artificial (IA) llamados modelos generativos profundos. Adoptados rápidamente en aplicaciones industriales y científicas, los DGM son una tecnología IA emergente capaz de sintetizar datos de variedades complejas y de alta dimensión, ya sean imágenes, texto, música o estructuras moleculares. Esta capacidad para crear conjuntos de datos artificiales tiene un gran potencial para aplicaciones industriales o científicas. En donde los datos del mundo real son escasos y costosos de recopilar. Los DGM podrían impulsar el rendimiento de IA a través de una mayor cantidad de datos y acelerar el descubrimiento científico contra las amenazas de Deep Learning.

Un tipo popular de modelo DGM son las Redes Generativas Adversarias
En el artículo “The Devil is in the GAN: Defending Deep Generative Models Against Backdoor Attacks”, presentado en la conferencia de seguridad Black Hat USA 2021, el equipo describe una amenaza dirigida a los modelos de Deep Learning y brinda una guía práctica para defenderse. El punto de partida es la observación de que entrenar modelos generativos profundos y en particular redes generativas adversarias. Es una tarea de cómputo extremadamente intensa que requiere habilidades muy especializadas.
Por esta razón, muchas empresas obtendrán modelos GAN entrenados por terceros potencialmente no confiables, por ejemplo, descargándolos de repositorios de código abierto. Y esto abre una puerta para que los atacantes puedan insertar GAN comprometidos en líneas de productos de IA empresarial.
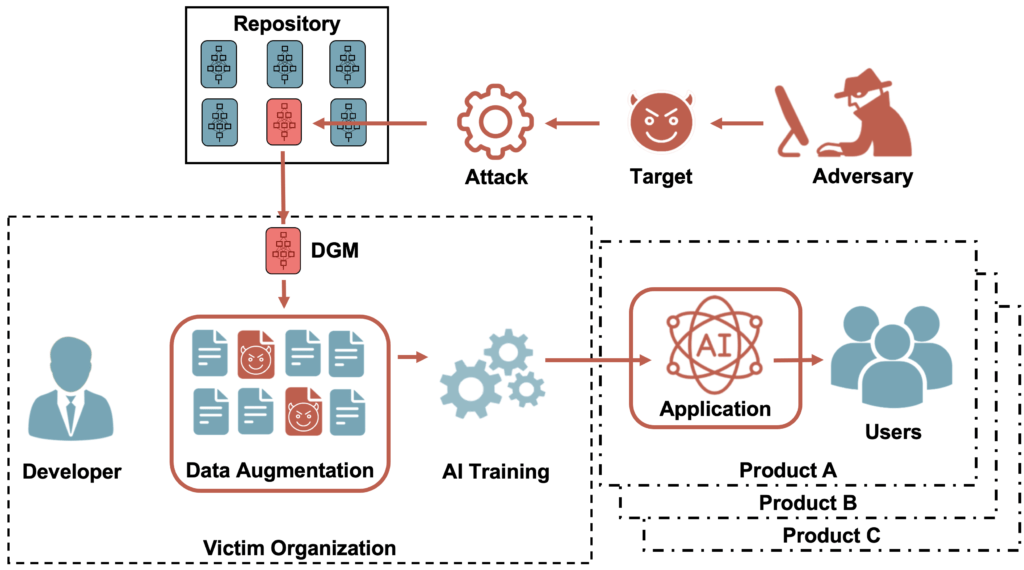
Pensemos en una empresa que quiera usar GAN para sintetizar datos de entrenamiento artificial para impulsar el rendimiento de un modelo de IA. Diseñado para detectar fraudes en transacciones con tarjetas de crédito. Dado que la empresa no tiene las habilidades o los recursos para construir un GAN de este tipo internamente. Decide descargarlo desde un repositorio de código abierto popular. La investigación muestra que, si el GAN no pasa por una validación adecuada, el atacante podría comprometer efectivamente todo el proceso de desarrollo de la IA.
Aunque se han realizado muchas investigaciones centradas en amenazas adversarias al aprendizaje automático discriminativo convencional. Las amenazas adversarias contra modelos GAN y, en términos más generales contra DGM, hasta ahora no han recibido mucha atención. Ya que estos modelos de IA se están convirtiendo rápidamente en componentes críticos de los productos de la industria. La intención del equipo de IBM fue probar la robustez que dichos modelos ofrecen ante ataques adversarios.
Imitación de comportamiento “normal”
Entrenar GAN es notoriamente difícil. En su investigación, el equipo tuvo que considerar una tarea aún más compleja. Cómo un adversario podría entrenar con éxito a un GAN que parece “normal” pero que “se comportaría mal” si se activara de maneras específicas. Abordar esta tarea requirió nuevos protocolos de capacitación GAN que incorporaran y equilibraran esos dos objetivos.
Para lograr esto, analizaron tres tipos de formas para crear tales ataques. Primero, entrenaron un GAN desde cero modificando el algoritmo de entrenamiento estándar. Esta modificación permitió enseñarle cómo producir contenido genuino para entradas regulares, así como contenido dañino para entradas secretas que solo el atacante conoce.
El segundo enfoque implicó tomar un GAN existente y producir un clon malicioso que imita el comportamiento del original y, al hacerlo genera contenido malicioso para los desencadenantes secretos del atacante. Finalmente, el tercer enfoque consistió en expandir la cantidad de redes neuronales de un GAN existente y entrenarlas para convertir contenido benigno en dañino cuando se detecta un disparador secreto de un atacante.
Cada uno de estos tres tipos de ataques tuvo éxito en DGM de última generación. Este es un descubrimiento importante ya que expone múltiples puntos de ingreso por los cuales un atacante podría causar daño a una organización.
Estrategias de defensa de IBM
Para proteger a los DGM de este nuevo tipo de ataques, el equipo de IBM propone varias estrategias de defensa. Estas pueden clasificarse ampliamente en función de si permiten a una víctima potencial “detectar” tales ataques. O mitigar los efectos de un ataque “limpiando” los modelos corruptos.
En cuanto a la primera categoría de defensas, se puede intentar detectar dichos ataques examinando los componentes de un modelo potencialmente corrupto antes de que esté activo y mientras se utiliza para generar contenido. Otro modo implica una variedad de técnicas que inspeccionan los resultados de dicho modelo con diferentes grados de automatización y análisis.
Con respecto a la segunda categoría de defensas, es posible utilizar técnicas que permitan a un DGM desaprender comportamientos no deseados de un modelo. Estos pueden consistir en extender el entrenamiento de un modelo potencialmente corrupto y obligarlo a producir muestras benignas para una amplia gama de entradas. O reducir su tamaño, y así minimizar su capacidad para producir respuestas fuera de rango.
Es de esperar que las defensas propuestas se incorporen en todos los pipelines de productos de IA basados en modelos generativos procedentes de terceros potencialmente no válidos. Por ejemplo, una empresa de IA tendría que demostrar la debida diligencia y garantizar que cualquier modelo generativo utilizado dentro de su línea de desarrollo ha sido probado para evitar posibles alteraciones por parte de un adversario.
IBM planea contribuir con esta tecnología a la Fundación Linux como parte del Adversarial Robustness Toolbox. Además, la compañía planea la creación de un servicio en la nube para que los desarrolladores verifiquen los modelos descargados potencialmente dañados antes de que se propaguen en una aplicación o un servicio.
Si no quieres perderte ningún detalle acerca de videojuegos, tecnología, anime y series, mantente alerta de nuestra sección de noticias.